Back
Speaker Recognition
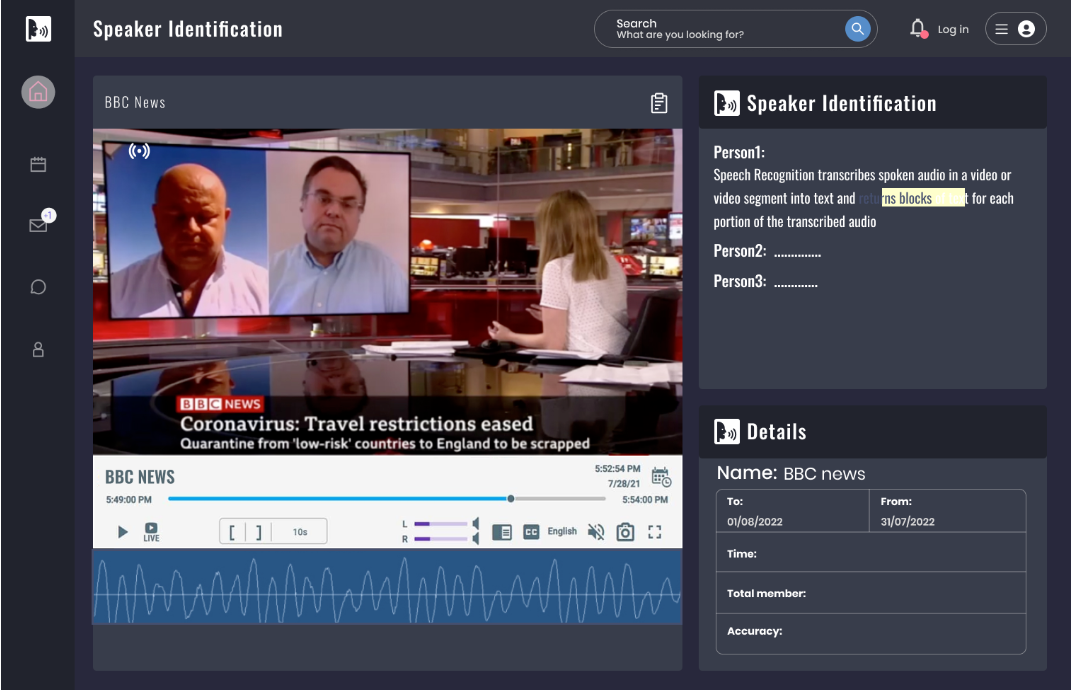
At Calbyte, we have developed a cutting-edge speaker identification system that accurately determines which registered speaker provided a given utterance from a set of known speakers. Our advanced technology leverages the latest advancements in voice recognition to deliver highly accurate results.
Tech Stack
Our speaker identification solution is built on a robust stack of technologies, including:
- Operating System: Linux
- Programming Languages: Python, C++
- Tool: Kaldi
- Framework: Custom-built for speaker identification
Our Use Case
In our specific use case, we have developed the speaker identification system for talkshow monitoring. This system accurately identifies the speakers in talkshows, enabling real-time monitoring and analysis of the content.
Real-World Applications
Our speaker identification system has a wide range of applications in various industries, including:
- Forensic Analysis: Identifying speakers in audio recordings for legal and investigative purposes.
- Access Control: Verifying the identity of individuals based on their voice.